emporiant

Preisgekrönte Innovation
„Die Zukunft wird nicht nur erträumt, die Zukunft wird gestaltet.“
Go Beyond Ordinary with…
Die ENTVISEK™-Engine.
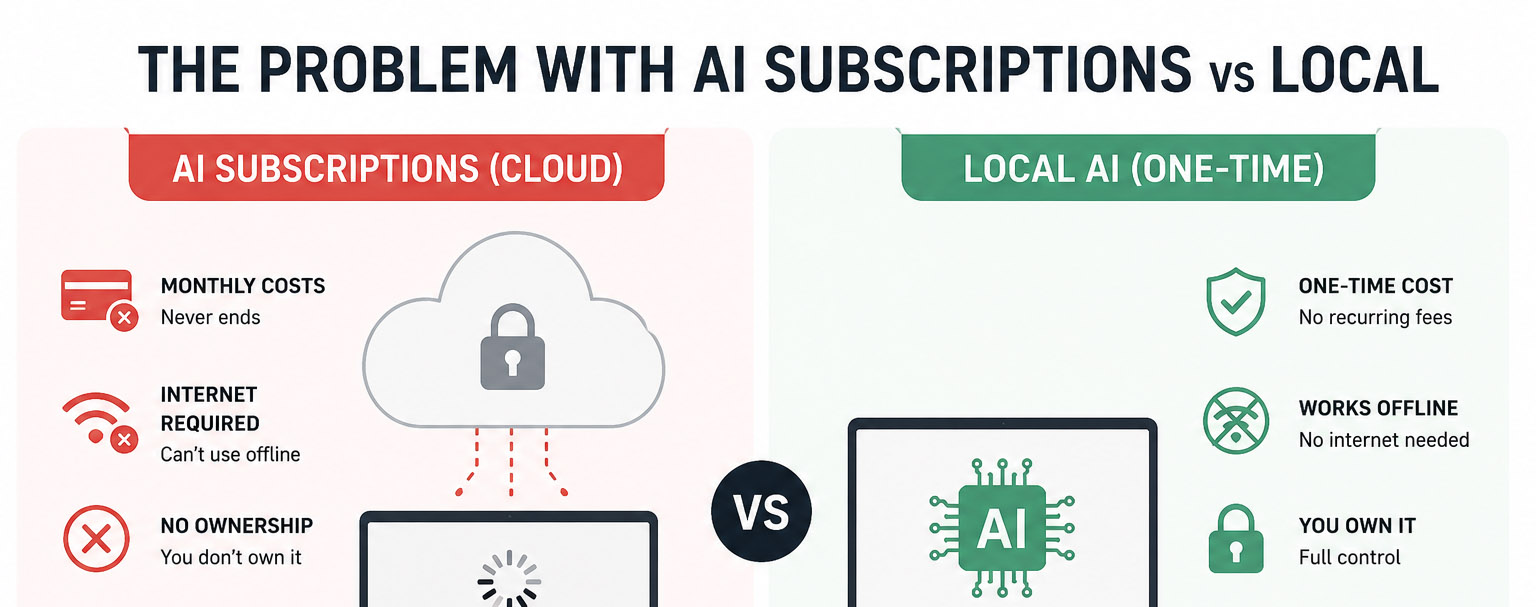
Entvisek ist eine vollständig intern entwickelte und lokal gehostete KI-Suite. Keine Cloud-Infrastruktur von Drittanbietern, keine Daten, die das eigene Land verlassen. In der DACH-Region, wo die Datenhoheit ein echtes geschäftliches Anliegen ist, ist ein lokal gehostetes KI-Tool mehr als nur eine technische Präferenz. Es bietet Unternehmen die Möglichkeiten moderner KI, ohne dass sie ihre Daten an ausländische Server weitergeben müssen – ein Angebot, mit dem die meisten Wettbewerber in der Region nicht mithalten können.
★★★★★ Kleine und mittlere Unternehmen sowie aufstrebende Firmen vertrauen darauf, dass wir ihnen regelmäßig wirkungsvolle Inhalte liefern – ganz ohne Stress.
Kurzinfo
So funktioniert ENTVISEK™

Schnelle
KI-Inferenz
Entvisek verarbeitet Ihre Anfragen lokal, direkt auf der Hardware in Ihrem Büro.
Keine Hin- und Rückübertragung zu einem Rechenzentrum in Virginia. Kein Warten darauf, dass ein Cloud-Server Kapazitäten freigibt. Textgenerierung, Dokumentenanalyse und Zusammenfassung erfolgen in der Professional-Stufe mit 18 bis 25 Tokens pro Sekunde – schnell genug, um sich wie ein echtes Gespräch anzufühlen und nicht wie ein Ladebildschirm. Ihre Daten bleiben vor Ort. Ihre Antworten erhalten Sie innerhalb von Sekunden.

KI-gestützte Steuerung
Das System verwendet nicht für alles ein und dasselbe Modell.
Entvisek wählt automatisch das richtige KI-Modell für die jeweilige Aufgabe aus – ein schlankes Modell für schnelle E-Mail-Entwürfe, ein Schlussfolgerungsmodell für komplexe Analysen, ein Spezialmodell für die Dokumentenverarbeitung. Sie müssen weder eine Auswahl treffen noch etwas konfigurieren. Sie stellen einfach Ihre Anfrage, und das System leitet diese an das Modell weiter, das am schnellsten das beste Ergebnis liefert. Eine Benutzeroberfläche, mehrere Engines im Hintergrund.

Benutzerbasierte Instanz
Jeder Mitarbeiter in Ihrem Büro erhält seinen eigenen privaten KI-Arbeitsbereich.
Die Finanzdaten Ihres Buchhalters kommen niemals mit der Kundenkorrespondenz Ihres Assistenten in Berührung. Die Authentifizierungsebene gewährleistet eine vollständige Trennung – unterschiedliche Benutzer, unterschiedliche Sitzungen, unterschiedliche Berechtigungen. Selbst auf einem gemeinsam genutzten Gerät. Das ist keine Einstellung, die Sie einfach umschalten können. So funktioniert die Architektur von Grund auf.

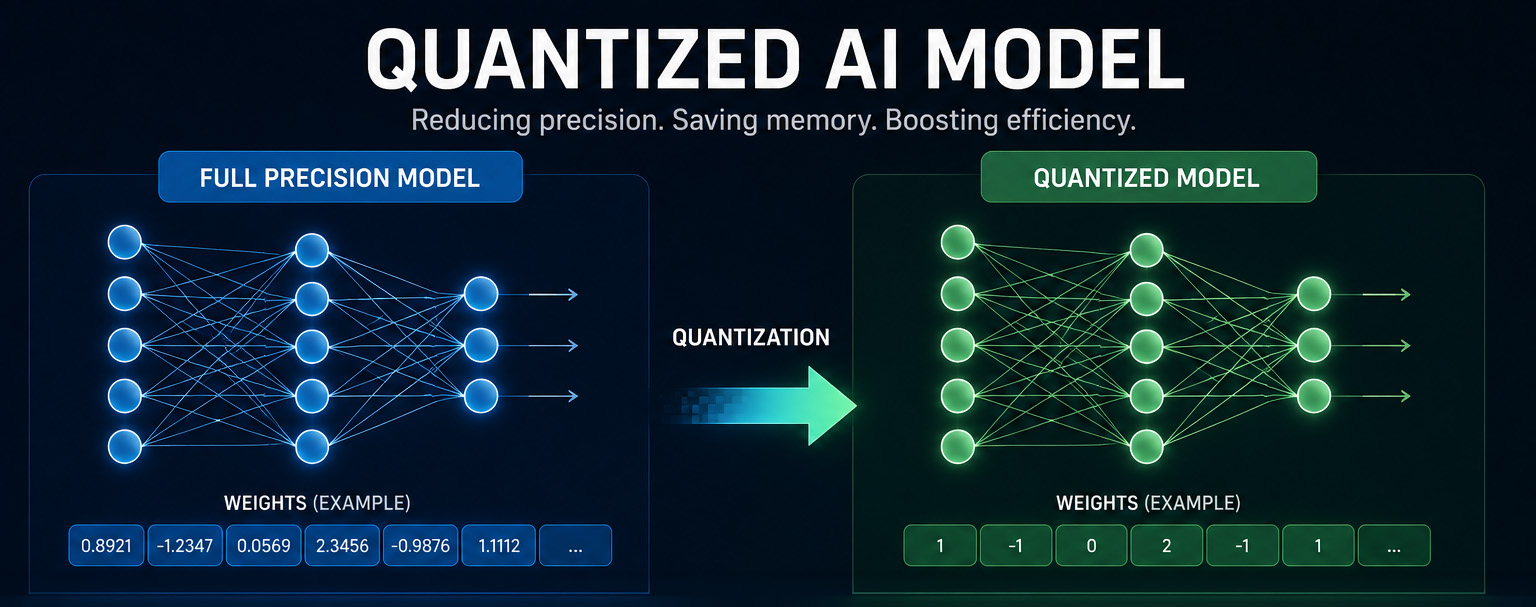
Quantisierte Modelle
KI-Modelle für den Unternehmensbereich erfordern in der Regel Serverräume voller GPUs.
Entvisek nutzt optimierte, quantisierte Versionen derselben Modelle – komprimiert, um auf Ihre Hardware zu passen, ohne dabei die entscheidende Leistungsfähigkeit einzubüßen. Ein Modell mit 14 Milliarden Parametern, das normalerweise 28 GB GPU-Speicher benötigt, läuft problemlos auf Ihrem Desktop. Gleiche Leistungsfähigkeit. Nur ein Bruchteil des Speicherplatzbedarfs. Kein Cloud-Abonnement erforderlich.
Emporiant AI
Den Weg für die Zukunft der lokalen KI.
Wir bei Emporiant AI sind davon überzeugt, dass die Zukunft der künstlichen Intelligenz dort liegt, wo die Daten entstehen. Wir sind spezialisiert auf lokale KI-Infrastrukturen, private KI-Implementierungen und Automatisierungslösungen der nächsten Generation, die Unternehmen dabei unterstützen, das Potenzial der KI voll auszuschöpfen, ohne dabei Abstriche bei Kontrolle, Sicherheit oder Leistung machen zu müssen.
Von lokal installierten Sprachmodellen bis hin zu intelligenten Geschäftsabläufen – unsere Lösungen sind darauf ausgelegt, Funktionen auf Unternehmensniveau zu bieten, wobei Sie die vollständige Kontrolle über Ihre Daten behalten. Wir verbinden bahnbrechende Innovationen mit praktischer Umsetzung und ermöglichen es Unternehmen so, KI sicher und effizient einzusetzen.
Vorreiter bei lokaler KI. Innovation vorantreiben. Die Zukunft gestalten.
Einzelunternehmer / Kleinstunternehmen (1–3 Nutzer)
Starter
€990
one-time
INCLUDES
- ✔ Leistungsstarke AMD Ryzen 9 PRO CPU
- ✔ Platzsparendes & Hocheffizientes Mini PC
- ✔ 16 GB RAM / 128 GB SSD
- ✔ Modell 7B (schnell, dialogorientiert)
- ✔ Emporiant AI Suite vorinstalliert
- ✔ Cluster-Verbindungsunterstützung
- ✔ Fernkonfiguration + 30 Tage Support
Kleines Team (3–8 Benutzer)
Professional
€1,490
one-time
INCLUDES
- ✔ Custom build w/ RTX 4060 Ti 16GB
- ✔ 32GB RAM / 1TB SSD
- ✔ Modelle 7B + 13B
- ✔ Emporiant AI Suite + RAG-Pipeline
- ✔ Unternehmensdokumente für die Q&A hochladen
- ✔ Installation vor Ort in der Steiermark
- ✔ 90 Tage Support inklusive
Wachsendes Team (8–20 Benutzer)
Enterprise
€2,490
one-time
INCLUDES
- ✔ Custom build w/ RTX 3090 24GB
- ✔ 64GB RAM / 2TB SSD
- ✔ Bis zu 70B-Modelle
- ✔ Vollständige RAG + Dokumentenerfassung
- ✔ Zugriffskontrolle für mehrere Benutzer
- ✔ Einrichtung vor Ort + Schulung
- ✔ 6 Monate Support inklusive
Einblicke in die KI
Architektur
– Einblicke.
Praktisches Denken von den Machern von Entvisek.
Wir veröffentlichen keine Nachrichten über KI. Wir schreiben darüber, was wir entwickeln – wie lokale KI tatsächlich funktioniert, warum Ihre Daten in Ihrem Büro bleiben sollten und was österreichische Unternehmen wissen sollten, bevor sie sich für ein weiteres Cloud-Abonnement entscheiden