

Es hat einen Grund, warum Enterprise-KI traditionell Serverräume erfordert hat. Ein typisches großes Sprachmodell — die Art, die ChatGPT oder Claude antreibt — hat Milliarden von Parametern. Jeder Parameter wird als Zahl gespeichert. Bei voller Präzision benötigt ein 14-Milliarden-Parameter-Modell etwa 28 Gigabyte Speicher allein zum Laden. Der Betrieb erfordert noch mehr. Deshalb bauen KI-Unternehmen massive Rechenzentren voller spezialisierter GPUs, die jeweils Zehntausende Euro kosten.
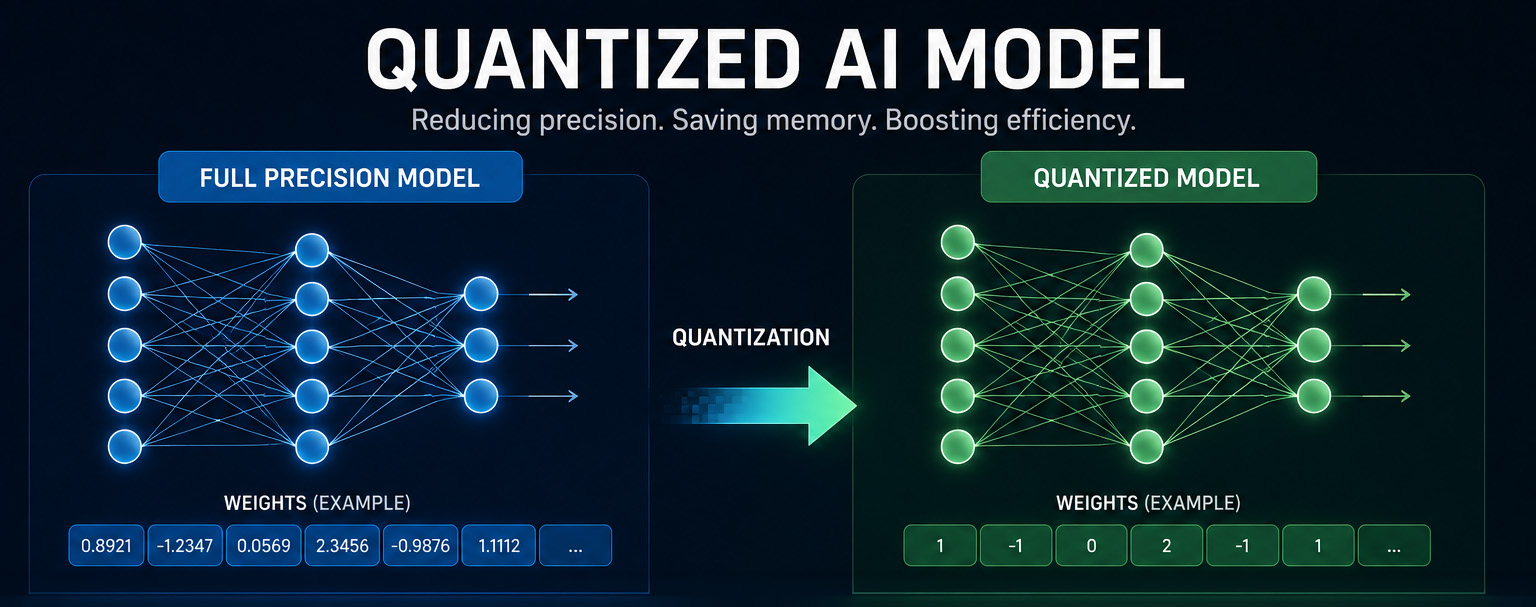
Quantisierung verändert die Rechnung.
Anstatt jeden Parameter als hochpräzise Gleitkommazahl (16 Bit oder 32 Bit) zu speichern, komprimiert Quantisierung sie in kleinere Darstellungen — 8-Bit, 4-Bit, manchmal sogar weniger. Ein 14-Milliarden-Parameter-Modell, das bei voller Präzision 28 GB benötigt, kann bei 4-Bit-Quantisierung in 8–10 GB laufen. Das ist der Unterschied zwischen einem Server-Rack und einem kompakten Gerät auf Ihrem Schreibtisch.
Die offensichtliche Frage: Zerstört die Komprimierung die Qualität?
Was Sie verlieren — und was nicht
Für die meisten geschäftlichen Aufgaben lautet die Antwort: Nein. Studien zeigen durchgehend, dass gut ausgeführte 4-Bit-Quantisierung 95–98 % der Leistungsfähigkeit eines Modells bei praktischen Aufgaben erhält — E-Mails entwerfen, Dokumente zusammenfassen, Fragen zu hochgeladenen Dateien beantworten, Berichte erstellen. Die Verluste zeigen sich in Randfällen — komplexe mehrstufige mathematische Schlussfolgerungen, seltene Sprachen mit begrenzten Trainingsdaten, hochspezialisierte akademische Bereiche. Für die Arbeit, die die meisten Unternehmen von KI benötigen — eine professionelle Antwort schreiben, Schlüsselzahlen aus einer PDF extrahieren, ein Angebot auf Basis einer Vorlage entwerfen — liefert das quantisierte Modell identische Ergebnisse wie die Vollversion.
Stellen Sie es sich wie Audiokomprimierung vor. Eine unkomprimierte WAV-Datei hat technisch eine höhere Qualität als eine MP3. Aber beim Musikhören im Auto, beim Pendeln oder im Büro können Sie den Unterschied nicht hören. Die Information, die bei der Komprimierung entfernt wird, ist Information, die Sie ohnehin nicht genutzt haben. Quantisierung funktioniert nach demselben Prinzip — sie entfernt Präzision, die das Modell für die Aufgaben, die Sie tatsächlich ausführen, nicht braucht.
Der Unterschied ist bedeutender, als die Qualitätslücke vermuten lässt. Modelle mit voller Präzision erfordern Hardware, die fünf- bis zehnmal so viel kostet. Sie verbrauchen mehr Energie. Sie erzeugen mehr Wärme. Sie erfordern Kühlinfrastruktur und dedizierte Serverräume. Quantisierte Modelle laufen auf Hardware, die in eine Schublade passt, an einer normalen Steckdose hängt und weniger kostet als ein High-End-Laptop.
Warum das die Wirtschaftlichkeit von KI verändert
Das ist es, was lokale KI als Produkt möglich macht — nicht nur als Forschungsprojekt. Vor fünf Jahren erforderte der Betrieb eines nützlichen Sprachmodells Cloud-Infrastruktur und ein laufendes Abonnement. Vor zwei Jahren brauchte man einen teuren Desktop mit einer High-End-GPU. Heute laufen quantisierte Modelle auf Hardware, die weniger kostet als ein Jahr Cloud-KI-Abonnement für ein kleines Büro.
Die Wirtschaftlichkeit hat sich umgekehrt. Die Frage ist nicht mehr: „Können wir es uns leisten, KI lokal zu betreiben?“ Sie lautet: „Können wir es uns leisten, weiterhin jemand anderen dafür zu bezahlen?“
Ein Cloud-KI-Abonnement für ein Fünf-Personen-Team kostet etwa 1.500 € pro Jahr. Das sind 4.500 € über drei Jahre — und am Ende dieser drei Jahre besitzen Sie nichts. Die Hardware-Alternative hat Anschaffungskosten, aber danach ist der laufende Aufwand Strom. Keine Gebühren pro Arbeitsplatz. Keine API-Messung. Keine Nutzungsobergrenzen. Ihr zehnter Mitarbeiter nutzt sie zum gleichen Preis wie Ihr erster.
Die Lücke schließt sich weiter
Quantisierungstechniken verbessern sich jedes Jahr. Die heute bei 4-Bit-Präzision verfügbaren Modelle übertreffen die Modelle mit voller Präzision von vor zwei Jahren. Die Entwicklung ist klar: kleiner, schneller, leistungsfähiger. Was heute auf einem Desktop läuft, wird morgen auf einem Laptop laufen. Was jetzt 16 GB Speicher braucht, wird nächstes Jahr 8 GB brauchen.
Unternehmen, die auf den „perfekten“ Moment warten, um lokale KI einzuführen, werden feststellen, dass dieser Moment vorbeiging, während sie Cloud-Abonnements bezahlten. Die Technologie kommt nicht erst. Sie ist da. Die Frage ist, ob Ihr Unternehmen sie nutzt — oder weiterhin bei jemand anderem mietet.
Schreibe einen Kommentar