

There’s a reason enterprise AI has traditionally required server rooms. A typical large language model — the kind that powers ChatGPT or Claude — has billions of parameters. Each parameter is stored as a number. At full precision, a 14-billion-parameter model needs roughly 28 gigabytes of memory just to load. Running it requires even more. That’s why AI companies build massive data centers filled with specialised GPUs costing tens of thousands of euros each.
Quantization changes the math.
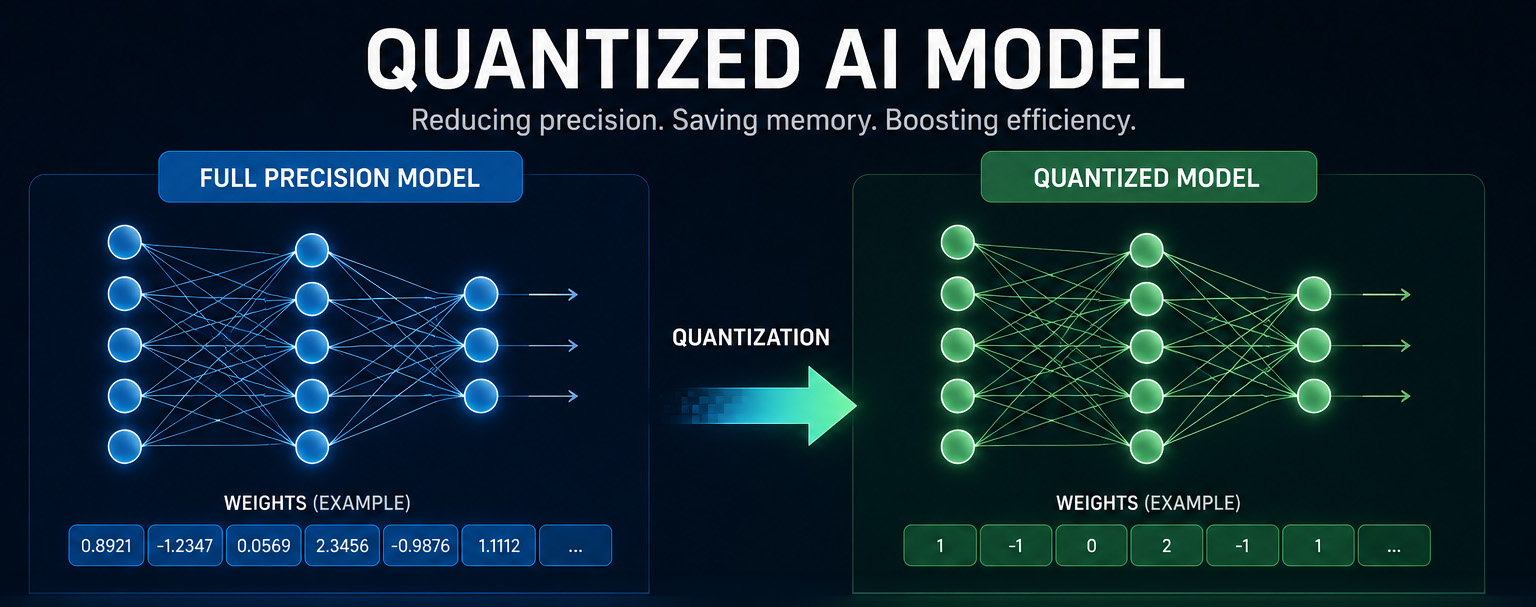
Instead of storing each parameter as a high-precision floating-point number (16 bits or 32 bits), quantization compresses them into smaller representations — 8-bit, 4-bit, sometimes even lower. A 14-billion-parameter model that needs 28GB at full precision can run in 8–10GB when quantized to 4-bit. That’s the difference between requiring a server rack and running comfortably on a compact machine sitting on your desk.
The obvious question: does compression destroy the quality?
What you lose — and what you don’t
For most business tasks, the answer is no. Research consistently shows that well-executed 4-bit quantization preserves 95–98% of a model’s capability on practical tasks like drafting emails, summarising documents, answering questions about uploaded files, and generating reports. The losses tend to show up in edge cases — complex multi-step mathematical reasoning, rare languages with limited training data, highly specialised academic domains. For the work most businesses need AI to do — write a professional response, extract key figures from a PDF, draft an offer based on a template — the quantized model performs identically to the full-size version.
Think of it like audio compression. An uncompressed WAV file is technically higher quality than an MP3. But for listening to music in your car, on your commute, or in your office, you can’t hear the difference. The information that gets removed during compression is information you weren’t using anyway. Quantization works on the same principle — it removes precision that the model doesn’t need for the tasks you’re actually running.
The difference matters more than the quality gap suggests. Full-precision models require hardware that costs five to ten times as much. They consume more energy. They generate more heat. They demand cooling infrastructure and dedicated server space. Quantized models run on hardware that fits in a drawer, plugs into a standard outlet, and costs less than a high-end laptop.
Why this changes the economics of AI
This is what makes local AI viable as a product, not just a research project. Five years ago, running a useful language model required cloud infrastructure and a recurring subscription. Two years ago, it required an expensive desktop with a high-end GPU. Today, quantized models run on hardware that costs less than a year of cloud AI subscriptions for a small office.
The economics have flipped. The question is no longer “can we afford to run AI locally?” It’s “can we afford to keep paying someone else to run it for us?”
A cloud AI subscription for a five-person team runs roughly €1,500 per year. That’s €4,500 over three years — and at the end of those three years, you own nothing. The hardware alternative has an upfront cost, but after that, the running expense is electricity. No per-seat fees. No API metering. No usage caps. Your tenth employee uses it for the same cost as your first.
The gap keeps closing
Quantization techniques are improving every year. The models available today at 4-bit precision outperform the full-precision models from two years ago. The trajectory is clear: smaller, faster, more capable. What runs on a desktop today will run on a laptop tomorrow. What requires 16GB of memory now will need 8GB next year.
Businesses that wait for the “perfect” moment to adopt local AI will find that the moment passed while they were paying cloud subscriptions. The technology isn’t arriving. It arrived. The question is whether your business will use it — or keep renting it from someone else.